
News
How to combine cohort studies?
by Mariëlle Zondervan-Zwijnenburg postdoc WP4
I enjoy developing methods that are helpful to other researchers
During my PhD at the Utrecht University Methodology and Statisticsdepartment, I became involved in a multi-cohort Consortium on Individual Development (CID) project. The aim was to examine parental age and child behaviour problems in four different CID cohorts (Generation-R, NTR, RADAR-Y and TRAILS). Combining results from multiple cohorts is easier said than done. It involves careful methodological consideration and that is where my expertise came in. Now, combining results across CID cohorts has become the main purpose of my postdoc.
 CID brings together large-scale longitudinal studies on child development. Some cohorts started recently (e.g., L-CID and YOUth), while others have been following children for over a decade (e.g., NTR, TRAILS, RADAR, Generation-R). The focus on child development ensures there is substantial overlap between the constructs assessed by the cohorts, but meta-analyses are not always possible due to variation in measures or selection of items.
CID brings together large-scale longitudinal studies on child development. Some cohorts started recently (e.g., L-CID and YOUth), while others have been following children for over a decade (e.g., NTR, TRAILS, RADAR, Generation-R). The focus on child development ensures there is substantial overlap between the constructs assessed by the cohorts, but meta-analyses are not always possible due to variation in measures or selection of items.
Combine at the hypothesis level with Bayesian methods
By combining the results at the hypothesis-level, we avoid the issue of data differences among different cohorts. If we can construct a set of competing hypotheses about our model results, we can apply Bayesian updating; an easy-to-use Bayesian research synthesis method.
- First, we need to compose a set of competing hypotheses about the parameters of interest.
- Subsequently, we evaluate the relative support for each hypothesis in each cohort.
- Finally, we update the evidence for the hypotheses across all cohorts which gives us the relative support for each hypothesis by all cohorts simultaneously.
This evidence reflects ‘robust evidence’, that is: the support becomes less dependent on the specific measure or the characteristics of the cohort at hand. This method for evidence synthesis with informative hypotheses was introduced by Kuiper et al 2012.
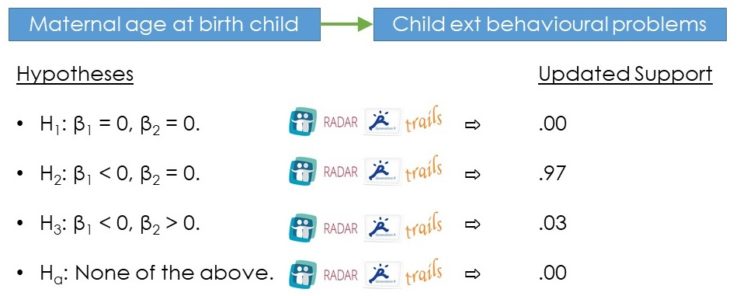 Updated evidence for one of the confirmatory phase analyses, here the evidence indicated that maternal age most likely has a negative association with behavioural problems. Figure designed by Mariëlle Zondervan-Zwijnenburg.
Updated evidence for one of the confirmatory phase analyses, here the evidence indicated that maternal age most likely has a negative association with behavioural problems. Figure designed by Mariëlle Zondervan-Zwijnenburg.
First application: combine results of four cohorts
The first time I applied this Bayesian method to combine cohort results was in a CID project about parental age (fathers and mothers separately) and child behaviour problems (internalizing and externalising separately). We kicked-off with a hands-on data analysis meeting. Over the course of an afternoon, we used R to clean data, started handling missing data (i.e., multiple imputation), and some even conducted their first exploratory analyses. To construct competing hypotheses, each cohort first explored 50% of their data (exploratory phase). Then, the relative support for each of the hypotheses was calculated in the other 50% of their data and combined across cohorts using Bayesian research synthesis (confirmatory phase). In this manner, we also performed a kind of cross-validation. In the end, this study was published in Child Development, and received world-wide media attention (including Daily Mail and US news).
Second application: closer to the exploratory results
Our second multi-cohort project was on parental age in relation to attention problems, IQ and educational achievement. The project was much like the first one, but differed in the use of the exploratory results. The first project took forward the hypotheses that were more or less apparent from all analyses. This meant that the same hypotheses were examined in all confirmatory phase analyses. Instead, the confirmatory phase of the second project included only the specific hypotheses that appeared from the exploratory results by the cohorts for a specific analysis (e.g., attention problems as reported by father regressed on maternal age), leaving a different set of hypotheses to evaluate in each analysis (i.e., paternal vs maternal age, child vs mother vs father vs teacher informants, and before vs after inclusion of SES and gender in the model). This resulted in a closer form of cross-validation where the exploratory phase really generated the hypotheses for each analysis, and the confirmatory phase validated those hypotheses that found support in the second half of the data. The manuscript resulting from this study is now under review.
Current challenge is a multi-cohort analysis of self-control
As part of the CID special issue, I am currently working on multi-cohort evidence synthesis for a longitudinal model on self-control. It will be based on three CID cohorts (RADAR, NTR and YOUth). This time, I analysed the data myself because the analyses were more complex and needed to be synchronised across cohorts. After tackling the different measurement intervals between cohorts as well as missing data, I also handled the different sets of items within cohorts over time. These and other challenges were worth it, as the first results are emerging. I am happy to tell you more at our next CID meeting on 14th November 2019!
I hope to contribute my expertise on evidence synthesis methods to future collaborative projects
Team effort
These projects are all very collaborative with help from several analysts, data-managers and principal investigators from all cohorts. The first multi-cohort study was conceptualized by my PhD supervisor Herbert Hoijtink with several principal investigators from work package 3. Sabine Veldkamp (PhD candidate with Dorret Boomsma at the VU Amsterdam) was an important partner in crime. She took the lead for the first project during my pregnancy leave, and we worked as a team from then on to complete the 2nd project. I have really enjoyed working together in CID, and I also enjoy developing methods such that they are helpful to other researchers. In the long run, I hope to be a part of collaborative projects and further elaborate upon the possibilities, restrictions and applications of research synthesis methods.
What’s next?
In the near future, I’m planning a project on social competence (e.g., pro-social behaviour) in relation to bullying or self-control. The decision to pursue this further depends on the theoretical value and the available data. The idea is to evaluate how these constructs relate to each other in a random-intercept cross-lagged panel or related model. I will conduct a simulation study to determine which model is appropriate for our data. Suggestions based on possibilities in multiple CID longitudinal cohort studies are very welcome!





