
News
FAIR, safe and high-quality data: The data infrastructure and accessibility of the YOUth cohort study
YOUth is a longitudinal cohort study in the Netherlands that aims to produce and safely store FAIR (Findable, Accessible, Interoperable and Reusable) and high-quality data. In this CID special issue article YOUth shares their experience and expertise in setting up a high-quality research data infrastructure for sensitive cohort data. Plus, also describe the procedures and the technical aspects of our data and data infrastructure. In doing so the authors highlight the importance of collaboration between organizations.
Academics involved in YOUth are monitoring the development and brain development of thousands of babies and children from the Utrecht area; a wide range of different data is being collected for this purpose. The type of data is very diverse: from questionnaires, video footage of child behaviour observations and the results of computing tasks, to 3D ultrasounds of babies in their mothers’ wombs, MRI scans and data from eye trackers. The object of all of the above? To identify which factors play a role in the development of children. YOUth optimises the usability of the data collected by making it available to as many academics as possible, without losing sight of the need to protect the privacy and rights of participants.
Different areas of expertise
The huge quantity of data generated by the YOUth research project is of interest for reuse by other researchers, at the UU and elsewhere. Developer Jelmer Zondergeld: ‘In accordance with the Open Science FAIR data principles, we ensure that the data generated by the YOUth research project is verifiable and suitable for reuse.’ The expertise of support staff from different disciplines has proved crucial to the success of this process.
Data in the vault: safe and structured
‘To be able to issue data for reuse, it must have been stored in a manner that makes them easy to verify,’ Jelmer Zondergeld explains. ‘For example, questionnaires are administered and stored very differently to 3D ultrasounds. Having said this, the ultimate aim is to have just one system on which all of this diverse data can be found.’ The ITS team at Utrecht University (Information and Technology Services) developed YODA for this purpose: an advanced digital infrastructure that can be used to protect, structure, integrate and store the different types of YOUth data. You could compare YODA to a vault to which just several people have access.
Data management
Once data has been stored verifiably, it must also be clear to users how this data was collected and made its way into the Yoda system. Data managers from the Research Data Management Support Team at the University Library manage the daily data requests received and have described the process involved in a data management plan. This plan provides an insight into the types of data collected, where and how often back-ups are made, among other things.
Adding meta data
A good description of the data collected helps new researchers decide whether or not they want to request it. A meta data expert from the University Library advises on how to make it easier to find YOUth data. The recently started metadata initiative will ensure that different CID cohorts use the same terms to describe their data. This will make data more searchable for academics.
Request and issue
The ultimate goal is to prepare FAIR and open data for reuse. Armed with clear data storage, work flow and descriptions on the one hand and funding from the Dynamics of Youth research theme, a programmer was able to take the last step and develop an online data-request and issue procedure, which will go live in the very near future. Researchers will then be able to request data much faster and easier.
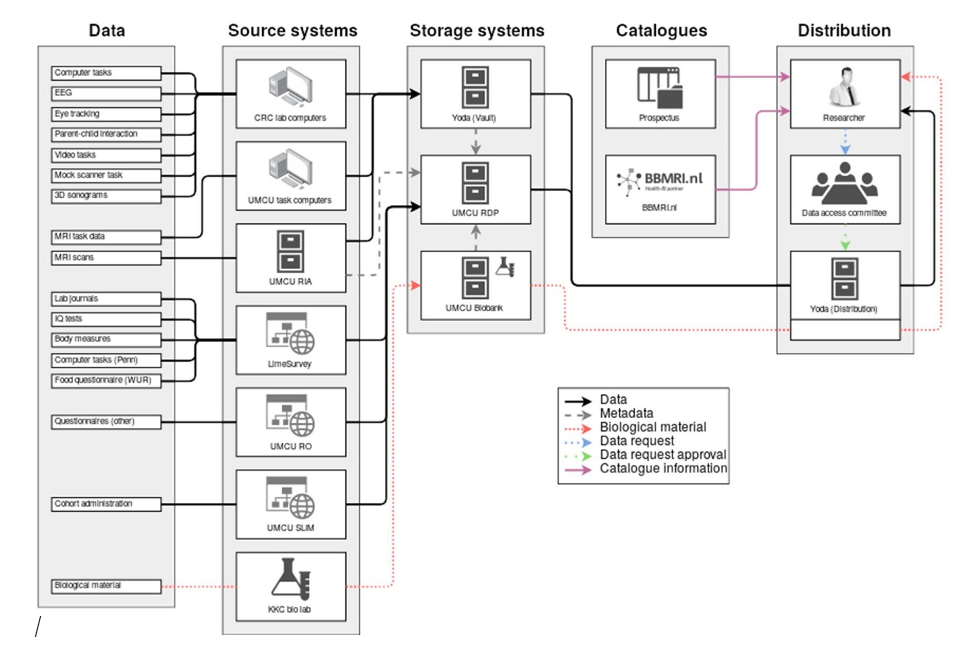
Figure 1: YOUth systems and data flows
More information
J. Zondergeld, Ron H.H. Scholten, Barbara M.I. Vreede, Roy S. Hessels, Harry A.G. Pijl, Jacobine E. Buizer-Voskamp, Menno Rasch, Otto A. Lange, Coosje L.C. Veldkamp (2020) FAIR, safe and high-quality data: The data infrastructure and accessibility of the YOUth cohort study Developmental cognitive neuroscience DOI: 10.1016/j.dcn.2020.100834
YOUth is part of the Utrecht University research theme Dynamics of Youth and part of UMC Utrecht Brain Center
This paper is part of a special issue in Developmental cognitive neuroscience about the Consortium on Individual Development. For an overview of all papers go to here.





